此篇博客用于记录小学期的python数据处理课程的大作业,上课的感觉就是和自学差不多了哈哈哈。所以就慢慢摸索吧!
环境介绍
Anaconda : 4.12.0Python : 3.9.12
作业要求
爬取百度百科中《乘风破浪的姐姐第二季》中所有嘉宾的信息,并对参演嘉宾名单及嘉宾信息进行可视化分析。
步骤
对参赛嘉宾名单及嘉宾信息进行爬取,对页面进行解析,获取嘉宾姓名和对应的百度百科链接
从演员个人百度百科页面爬取数据,对每个嘉宾进行解析,获取嘉宾的个人信息,如民族、星座、身高、体重等
分析所有嘉宾数据并进行可视化(如绘制年龄分布、体重分布等等)
具体实现 爬取网页内容并解析页面 所需模块
requests:一个简单易用的HTTP库,可以发起请求并返回服务器响应内容。BeautifulSoup:可以从HTML或XML文件中提取数据的Python库。
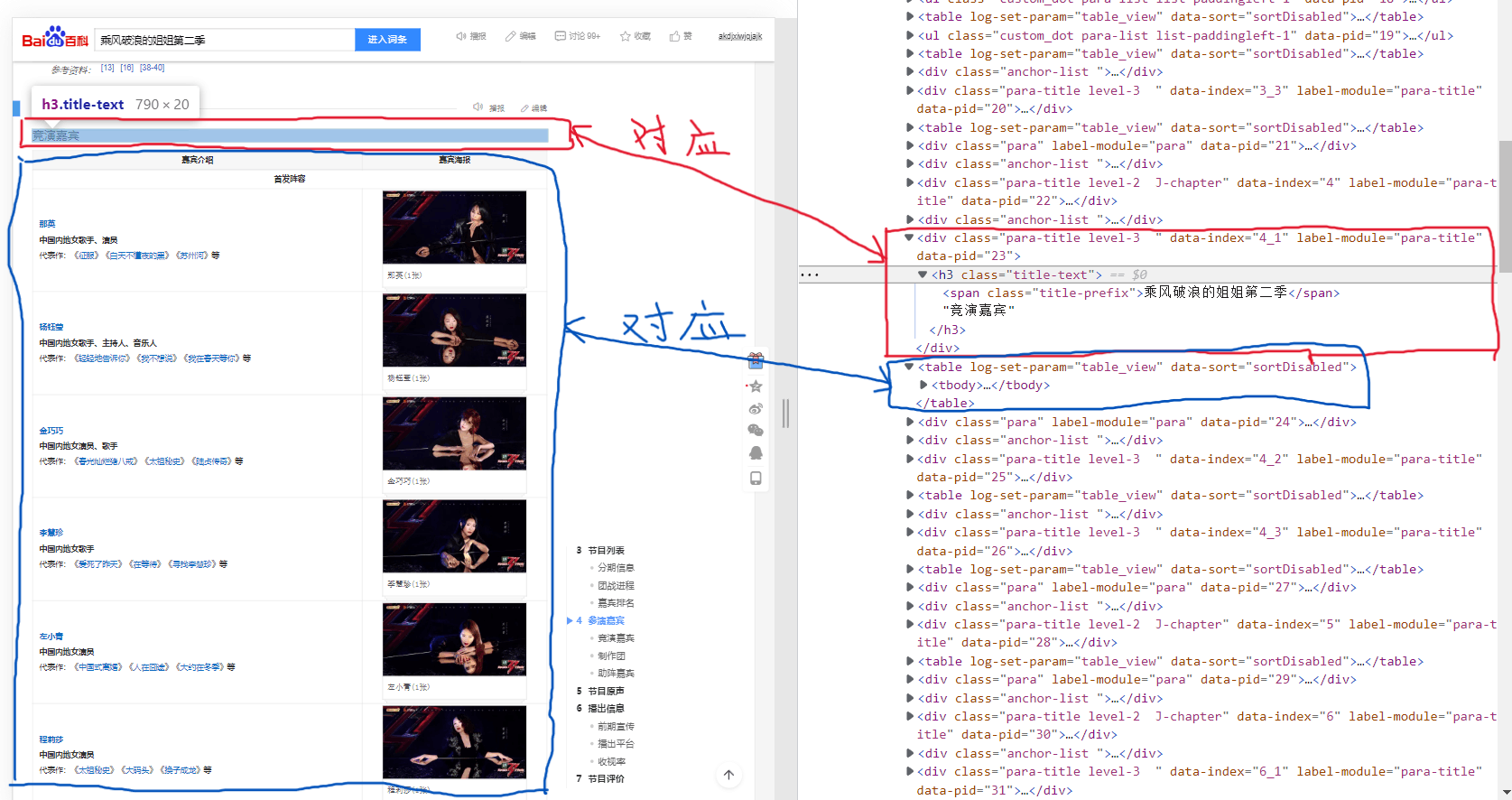
思路 要获取网页中的信息并进行解析,那么首先就是先看看目标网页中我们需要哪些元素。打开百度百科乘风破浪的姐姐第二季 ,可以在标题为 “竞演嘉宾” 的表格里找到我们想要的关于参赛人员的相关信息。但这不是唯一的表格,所以我们还需要在后续对数据进行筛选。
那么我们的目标就确定了:首先获取网页内容,找到其中所有的表格属性,再根据表格标题进行筛选,最终找到所需数据,为下一步做准备。
根据我们的思路,首先就要获得网页的内容。可以使用requests.get(url)函数发起一个http get请求,并返回响应内容。在这里我们要加上一个包含用户代理(User-Agent)的请求头,否则百度百科会拒绝我们的请求。
获取了网页内容后,我们需要找到其中所有的表格属性。HTML中以<table>标签表示表格,所以我们可以使用BeautifulSoup.find_all()函数来找到所有的表格以及其子属性。
最后就是进行筛选。F12快捷键打开网页源代码,可以注意到所有表格的标题属性都在表格属性的前一个的位置:
find_previous()恰好函数可以帮助我们找到一个元素前方的元素。这样我们就完成了第一步:找到并获取所需要的数据。
源代码 具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def get_table (): headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } url='https://baike.baidu.com/item/乘风破浪的姐姐第二季' response = requests.get(url,headers=headers) soup = BeautifulSoup(response.text,'html.parser' ) tables = soup.find_all("table" ) table_title = "竞演嘉宾" for table in tables: table_titles = table.find_previous('div' ).find_all('h3' ) for title in table_titles: if table_title in title: return table
获取嘉宾基础信息 思路 这一步其实与第一步中查找所有表格类似,利用BeautifulSoup.find_all()函数查找表中所有行,再找行中所有单元格,最后找单元格中的块,块的内容就是我们需要的内容。
但是,这里还有两个小问题。
第一个问题是这个表格中有一行为 “踢馆阵容” ,其中没有我们需要的数据,需要跳过这一行。
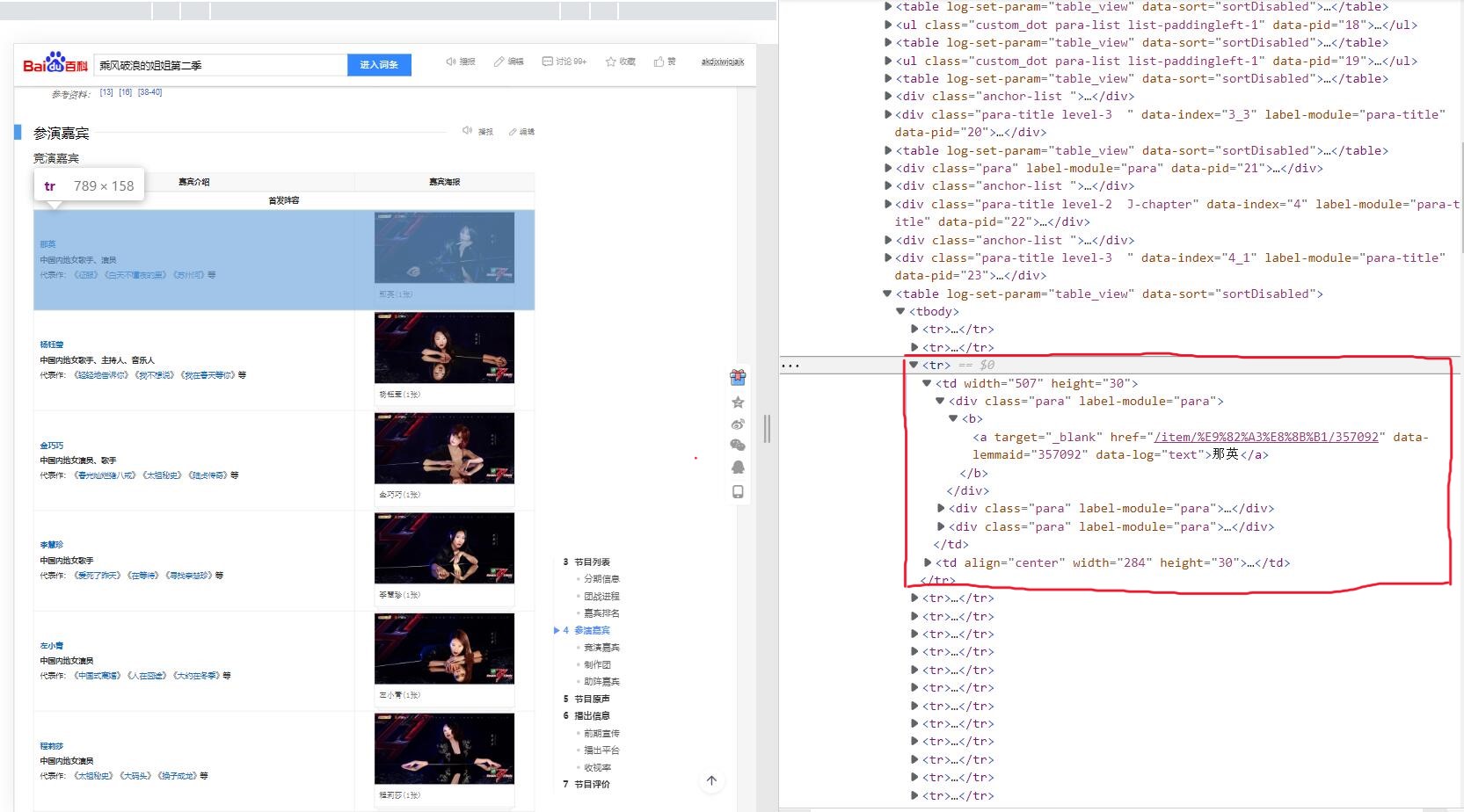
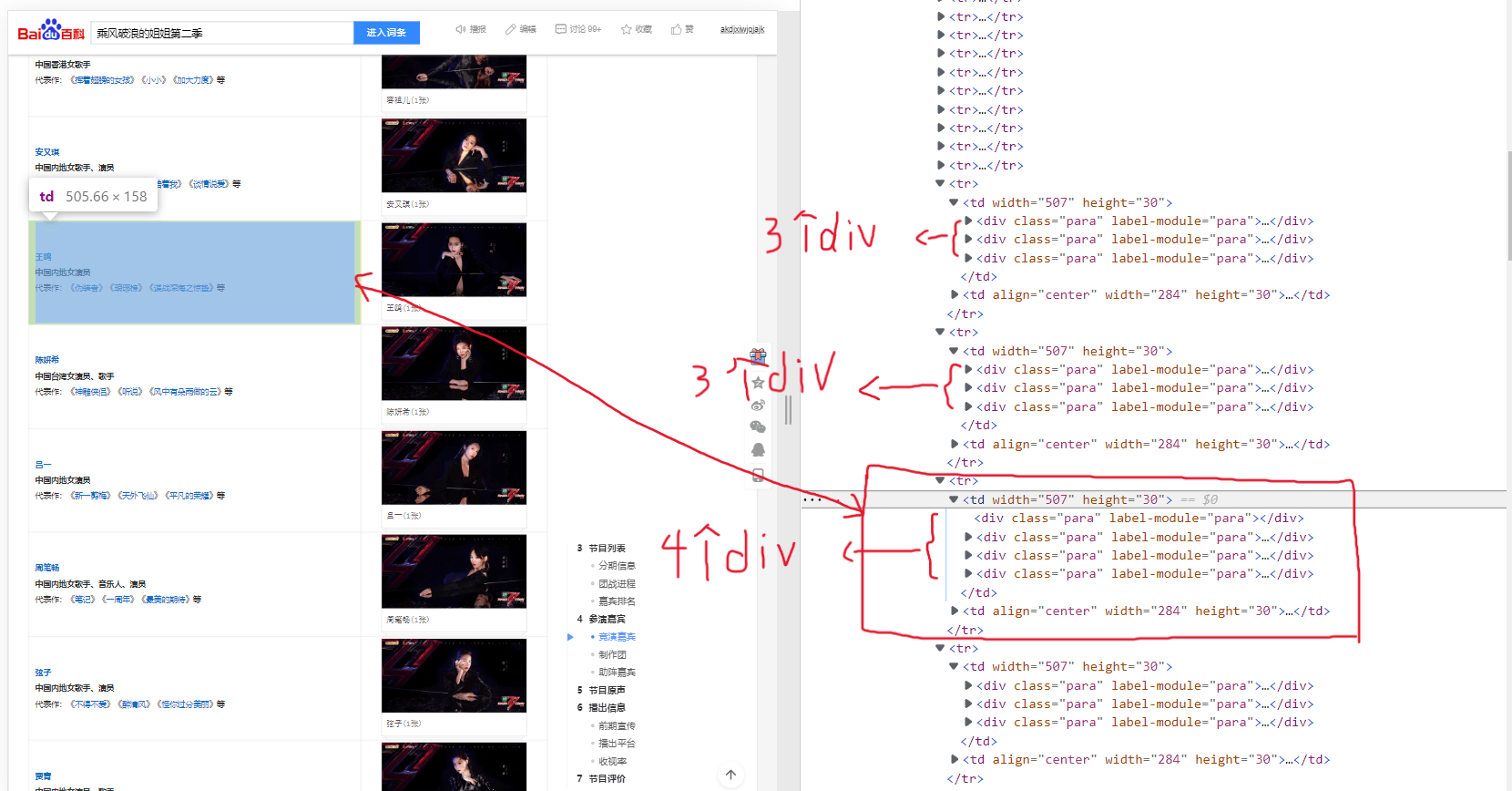
第二个问题是“王鸥”所在的单元格。
从图中可以看出,“王鸥”的单元格中有四个<div>,而其他单元格中一般只有三个。我不明白这是为什么,也没明白这个多余的<div>有什么用,他的存在好像就是给我添了个麻烦。而且菜鸡如我也没想到什么好的解决办法,就只好利用一个计数器,当计数到他时单独进行处理。
源代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 count = 2 def get_table_data (table_html ): bs = BeautifulSoup(str (table_html),'html.parser' ) all_trs = bs.find_all('tr' ) members = [] for tr in all_trs[2 :]: global count count = count + 1 all_tds = tr.find_all('td' ) all_divs = all_tds[0 ].find_all('div' ) if all_divs[0 ].text == '踢馆阵容' : continue member = {} if count == 15 : member["name" ] = all_divs[1 ].text member["link" ]= 'https://baike.baidu.com' + all_divs[1 ].find('a' ).get('href' ) member["job" ] = all_divs[2 ].text member["describe" ] = all_divs[3 ].text else : member["name" ] = all_divs[0 ].text member["link" ] = 'https://baike.baidu.com' + all_divs[0 ].find('a' ).get('href' ) member["job" ] = all_divs[1 ].text member["describe" ] = all_divs[2 ].text members.append(member) return members
根据嘉宾个人链接获取详细信息 思路 到了这一步,大体的实现思路已经与之前获取网页中表格的信息时的思路相差不大了,都是在网页中找到目标信息的位置,然后利用find_all()、find()、find_next()、find_previous()等函数进一步查找,最后利用对象的.text属性来获取数据。所以这里只说一些和之前不同的地方。
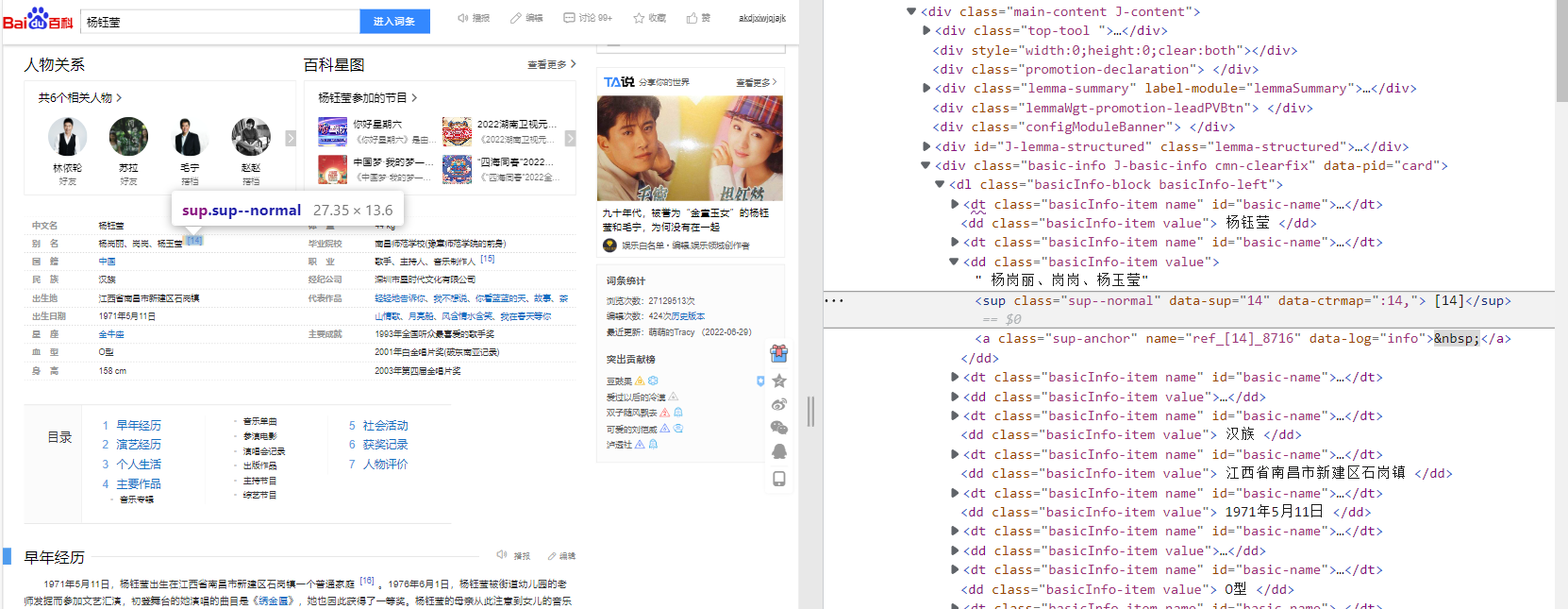
第一个不同之处在于个人网页里的信息存在于一个描述列表里,而这个列表里的某些数据存在上标,如图:
所以为了我们数据格式的一致性,需要去除这些上标。而去除上标,说白了就是将爬取的数据中的特殊标签及其内容全部舍弃掉。
F12快捷键查看网页源代码,可以看到上标属性在HTML中是以标签<sup>表示的。
那我们要做的就是找到所有的<sup>标签并且删除他。通过以下代码就可以做到我们想做的:
1 2 for s in soup('sup' ): s.extract()
第二个不同之处在于HTML中表示空格的 。
可以看到在“民”、“族”之间有四个 ,表示四个空格。在jupyter中使用print()函数打印时也确实有空格。但当我试图利用带四个空格的字符串(例如:“民 族”)与他进行匹配时却失败了。我也尝试了用四个 代替四个空格,也失败了。最后查了资料 才知道要把它替换掉。
替换方法如下:
1 dt.text.replace(u'\xa0' , '' )
dt为包含 的解析后的HTML元素。
初次之外,该方法还可以去除文本中的换行符,这也是一个非常重要的用途。
源代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def get_members_information (members ): print ("get members information..." ) headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } target_info = ["民族" , "出生日期" , "星座" , "身高" , "体重" , "经纪公司" ] for member in members: response = requests.get(member["link" ],headers=headers) soup = BeautifulSoup(response.text,'html.parser' ) for s in soup('sup' ): s.extract() all_info = soup.find_all('div' , attrs = {'class' :'basic-info J-basic-info cmn-clearfix' }) for info in all_info: all_dl = info.find_all('dl' ) for dl in all_dl: all_dt = dl.find_all('dt' ) for dt in all_dt: basic_info = dt.text.replace(u'\xa0' , '' ) if basic_info in target_info: dd = dt.find_next("dd" ) data = dd.text.replace("\n" ,"" ) data = data.replace(u'\xa0' ,'' ) member[basic_info] = data result = pd.DataFrame(members) return result
这一步做完,就获得了我们需要的数据,接下来就是对具体的数据进行清洗、整理、可视化的过程了。
处理数据 思路
处理获得的几种数据的思路是相同的,所以这里就以最难处理的日期数据为例,其他数据的处理过程都可以根据这个例子来进行。
之前我们获取的日期数据格式并不整齐,其中有的数据包含了阴历生日,有的可能没有对应的数据。
这就要求我们先去除Na值,然后将日期数据统一为xx年xx月xx日的格式,并利用strptime()函数将日期从字符串解析为时间元组。获取了时间元组后与今天的年份相减就可以得到年龄。然后就可以进行分箱,最后根据需求来绘图即可,这里选则绘制柱状图。
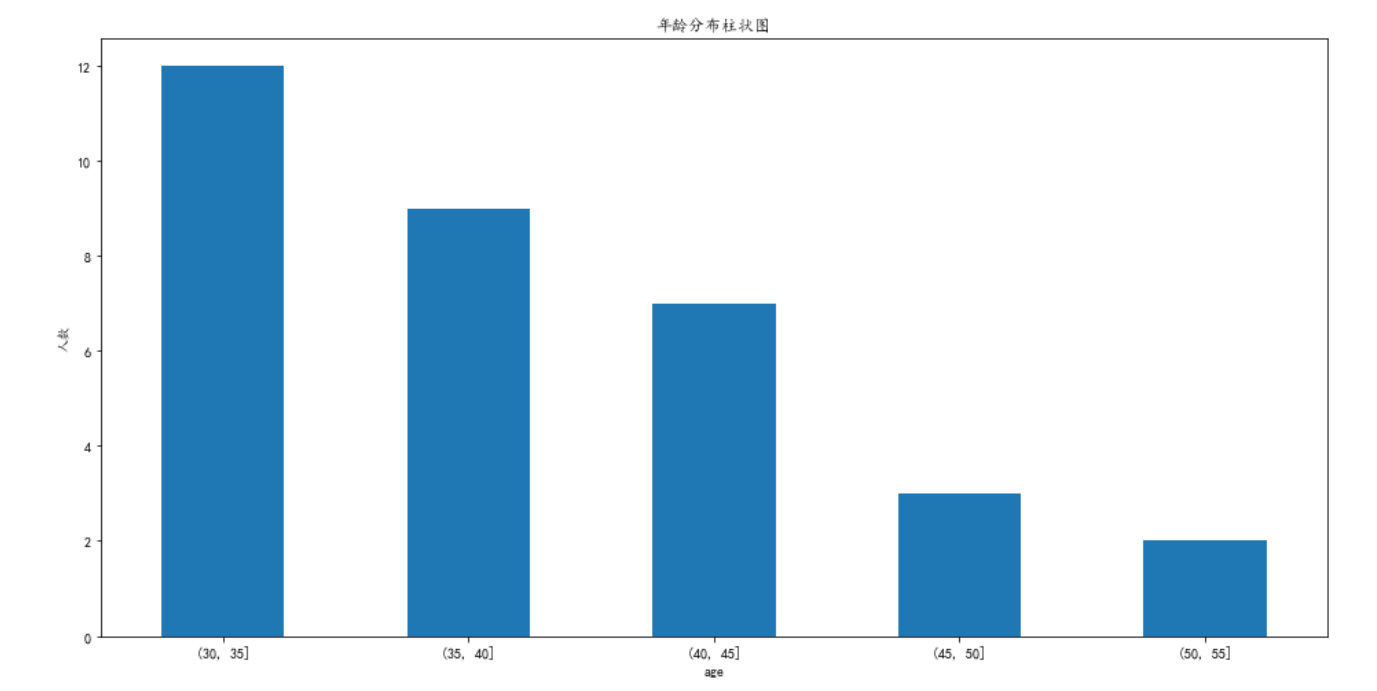
源代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def date_process (data ): print ("date processing..." ) for i in range (len (data["出生日期" ])): pos = str (data["出生日期" ].iloc[i]).find("日" ) data["出生日期" ].iloc[i] = str (data["出生日期" ].iloc[i])[:pos+1 ] for i in range (len (data["出生日期" ])): data["出生日期" ].iloc[i] = datetime.datetime.strptime(str (data["出生日期" ].iloc[i]),'%Y年%m月%d日' ) age = pd.DataFrame(index = data["name" ], columns = ["age" ]) for i in range (len (data["出生日期" ])): age.iloc[i]["age" ] = datetime.datetime.now().year - data["出生日期" ].iloc[i].year bins = [30 ,35 ,40 ,45 ,50 ,55 ] cats = pd.cut(age["age" ],bins) df1 = age.groupby(cats)["age" ].count() plt.rcParams['font.sans-serif' ]=['SimHei' ] plt.figure(figsize=(16 , 8 )) plt.title('年龄分布柱状图' ) plt.xlabel("年龄" ) plt.ylabel("人数" ) df1.plot(kind='bar' , rot=0 ) plt.show
结果:
其他数据的处理方式大体相同,最后的图形绘制可以选择柱状图、散点图、饼图等,具体的选择还要根据需求来决定。
总结 个人感觉这个活还是需要随机应变,因为面对的数据太多,不可能对每一个都去看源代码找特殊之处,还是要在写代码过程中多通过print()来查看数据有什么奇怪的地方,及时修改。最后用一个词总结就是见招拆招 。